Handheld data collection systems, such as the Universal Manipulation
Interface (UMI), enable scalable data collection across diverse
environments but only capture observed actions rather than
the desired actions executed by a robot controller. In
contrast, teleoperation captures desired actions directly, but is
prohibitively time-consuming to collect. We revisit this trade-off
through the lens of label validity across task phases. We
observe that handheld trajectories provide valid supervision in
tolerant, free-space phases, but lack dynamic feasibility in
contact-sensitive phases, where tracking observed trajectories at
high stiffness produces large, unsafe contact forces. We study the
interaction between these two supervision types for contact-rich
manipulation and find that training policies that combine handheld
data with a small number of targeted teleoperated demonstrations
provides an efficient hybrid strategy. Specifically, rather than
teleoperating the entire task, we only collect partial teleoperated
demonstrations for task segments where base handheld policies fail.
However, naively mixing handheld and teleoperated phase-specific
data yields worse performance than training on handheld data alone.
To address this mismatch between observed and desired supervision,
we propose Bi-modal Routing for Imitation Data via Gated
Experts (BRIDGE), a mixture of diffusion policy experts
that routes between specialist task phase heads conditioned on the
current robot state. Notably, our approach produces measurably
lower end-effector forces under contact and improves success rates
over handheld-only baselines by up to 36.7% across
three contact-rich manipulation tasks.
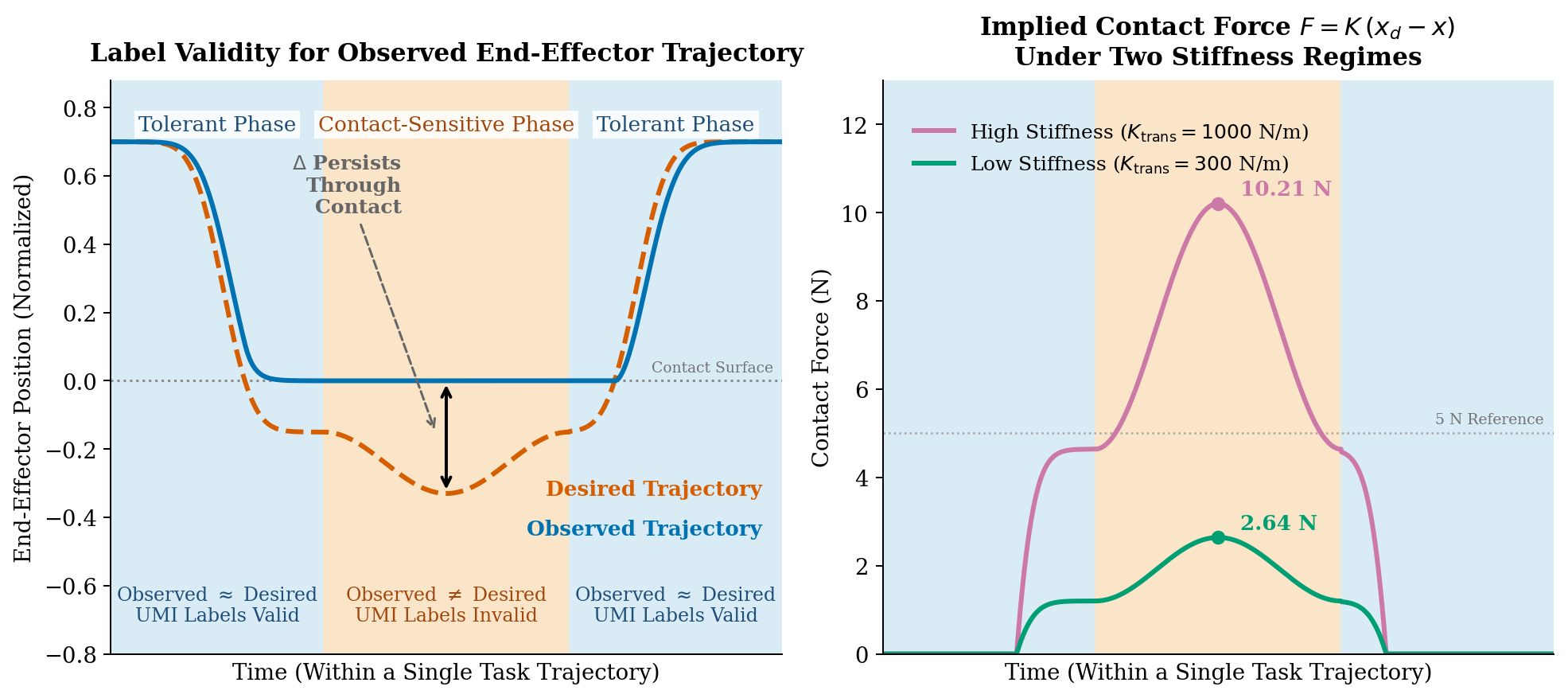
Key Insight: Action Validity
Handheld devices record observed actions (where the
end-effector actually went), while a robot controller is driven by
desired actions (the reference it is commanded to track). In
free-space, tolerant phases the two coincide, so
observed handheld labels are valid supervision. In
contact-sensitive phases they diverge: the desired
position drives into the contact surface while the observed position is
held above it. Tracking the observed trajectory at the stiffness needed
to follow it then produces large, unsafe contact forces. This is why
handheld-only labels fail precisely where contact matters — and
why targeted teleoperation, which captures desired actions directly, is
uniquely valid there.
Action Validity Under Contact.Left: observed and desired end-effector trajectories agree in
tolerant phases but diverge persistently during contact, where handheld
labels become invalid. Right: the same gap becomes contact
force via \(F = K(x_d - x)\) — high stiffness tracks closely but
spikes to ~10.2 N, while compliant stiffness peaks at ~2.6 N
but cannot track through contact.
Method
We present a dual-mode data collection setup for contact-rich
manipulation and introduce BRIDGE, a mixture-of-experts
policy that jointly learns from handheld and teleoperated supervision.
DM-UMI: Dual-Mode Data Collection Device
UMI relies on offline monocular SLAM for trajectory reconstruction and
ArUco-tag detection for gripper-width estimation. While this enables
in-the-wild data collection, it requires offline processing for camera
pose and gripper width — both incompatible with online
teleoperation. We design Dual-Mode UMI (DM-UMI) to
support both modes from a single device:
An XVISIO DS80 SLAM camera replaces offline SLAM,
providing 6-DoF pose at 500 Hz via onboard stereo
visual-inertial odometry.
A linkage-based gripper with magnetic position
sensors replaces the rack-and-pinion mechanism for smoother,
backlash-free actuation and precise width measurement.
An IDS RGB fisheye camera with low-level camera
control replaces the GoPro + HDMI-capture-card path, reducing
latency and enabling tight time synchronization. The fisheye optics
match the GoPro’s, allowing interoperation with public UMI
datasets.
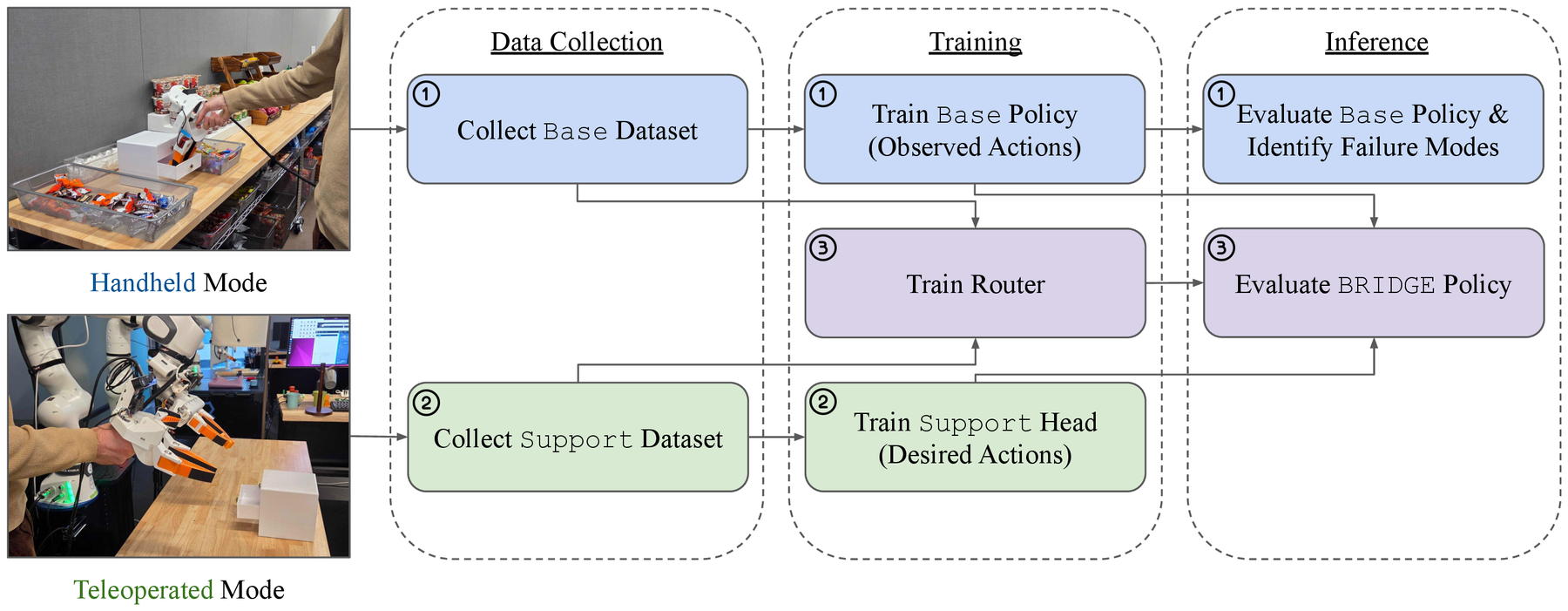
Dual-Mode Data Collection Pipeline.
We collect a base dataset via handheld mode, identify
failure modes, then collect a targeted support dataset
via teleoperation. The base policy, support
head, and router compose the BRIDGE model.
Dataset Collection
The base dataset is collected in
handheld mode across diverse environments, capturing only observed
actions. Broad coverage, low cost per trajectory.
The support dataset is collected in
teleoperated mode, targeted at base-policy failure
modes. It captures both observed and desired actions, isolating
embodiment-specific effects (controller dynamics, kinematics,
contact dynamics, grasp stability).
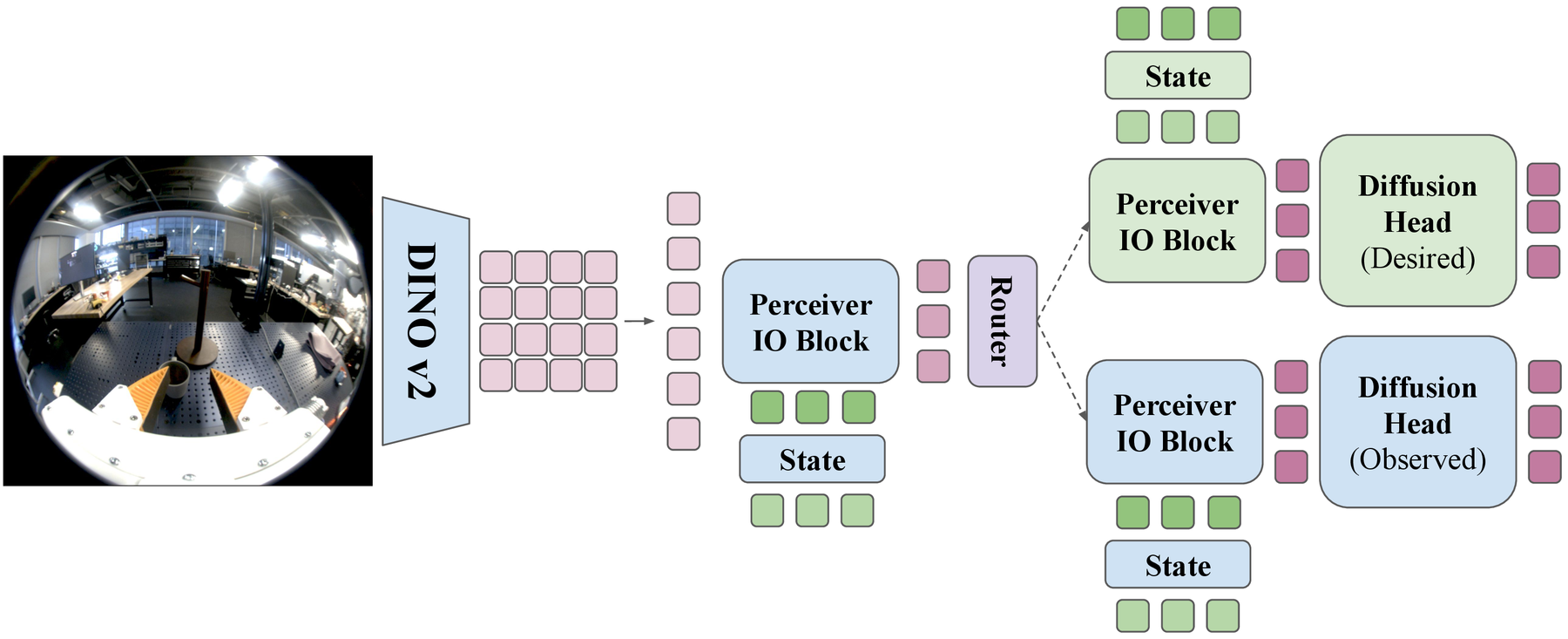
Stage 1: Base Policy Training
Our base policy extends Diffusion Policy. We retain the full set of
spatial patch tokens from a DINOv2 vision encoder (rather than only the
CLS token) to preserve spatial structure needed for contact-rich
reasoning. A PerceiverIO-style aggregation reduces \(V \in
\mathbb{R}^{B \times N \times D}\) tokens to a small set of learnable
queries \(Q \in \mathbb{R}^{B \times M \times D}\), \(M \ll N\), via
stacked cross-attention. State inputs (end-effector pose, gripper
width) are projected and cross-attended with the vision tokens to
produce the conditioning latent \(Z_\text{latent}\), which feeds a
temporal diffusion head trained with the standard diffusion loss on
the base dataset.
Stage 2: Support Head Training
With the base expert \(\pi_b\) and shared vision encoder frozen, we
train a support latent adapter \(\phi_s\) and head
\(\pi_s\) on the support dataset. The action target is
the desired trajectory, \(\hat{a}^s_{t:t+H} = \pi_s(c^b_t)\). The
support expert is optimized independently with its own diffusion loss.
Stage 3: Router Training
An MLP gate \(G_\psi(z_t)\) routes observations to the appropriate
expert. To label samples, we extract intermediate latents
\(Z_\text{latent}\) from the base policy on both datasets, filter
overlapping base latents using a \(k\)-NN classifier
(\(k=16\), distance \(\epsilon=0.8\)), then define a support score:
We distill the \(k\)-NN classifier into \(G_\psi\) with binary
cross-entropy on \(\rho(z_t)\).
Inference
At inference, each observation \(o_t\) is encoded into a shared
\(Z_\text{vision}\) used to produce the router latent. The router
emits gating predictions \(g_{t:t+H}\). Given threshold \(\eta\), we
hard-switch between experts:
Unlike residual learning — which requires every expert to model
the entire task — the hard switch lets each expert specialize
locally.
Model Architecture.
BRIDGE extends Diffusion Policy to dynamically route between predicting
observed and desired actions. We sequentially train the
base model, collect targeted
teleoperated demonstrations to train the
support head, and finally train
the router.
Tasks
We evaluate on three precise, contact-rich tasks on a Franka FR3 arm
running a Cartesian impedance controller. Each concentrates difficulty
in a short contact-sensitive phase bracketed by free-space motion.
NIST Pulley Routing
Grasp a deformable O-ring and route it around the
pulleys while maintaining constant tension (NIST Assembly Task
Board #2).
Pipe Insertion
Grasp a pipe and insert it into a tight-tolerance
opening, requiring reliable grasping, 6-DoF alignment, and
force-aware insertion.
Battery Insertion
Pick up an AA battery and seat it in a spring-loaded
compartment, keeping the spring compressed while the battery is
seated.
Results
BRIDGE consistently outperforms handheld and naive-mixing baselines and
recovers much of the gap to a full-teleoperation upper bound —
even though its sparse support data covers under 15% of the
end-effector path length. Naively mixing observed and desired labels in
a single head degrades performance, often below the
handheld-only policy, motivating state-gated routing instead.
Task Success Rate
Method
NIST Pulley
Pipe Insertion
Battery Insertion
Base Policy (Handheld)
44.0%
13.3%
10.0%
Naive Mix
0.0%
6.7%
0.0%
BRIDGE (Ours)
76.0%
50.0%
33.3%
Base Policy (Teleoperated)†
84.0%
63.3%
40.0%
†Full-task teleoperation upper bound, collected under an
approximately time-matched data budget. Each task is evaluated over
25–30 rollouts across shifted fixture positions.
Dataset Statistics
Task
Base #
Support #
Teleop #
Support Temporal %
Support Dist. %
NIST Pulley Routing
201
50
60
37.8%
7.4%
Pipe Insertion
100
81
60
24.5%
3.4%
Battery Insertion
290
59
100
61.1%
14.9%
support data spans a large temporal fraction (slower
teleoperation rate) yet remains spatially sparse, covering only a small
fraction of the end-effector path length.
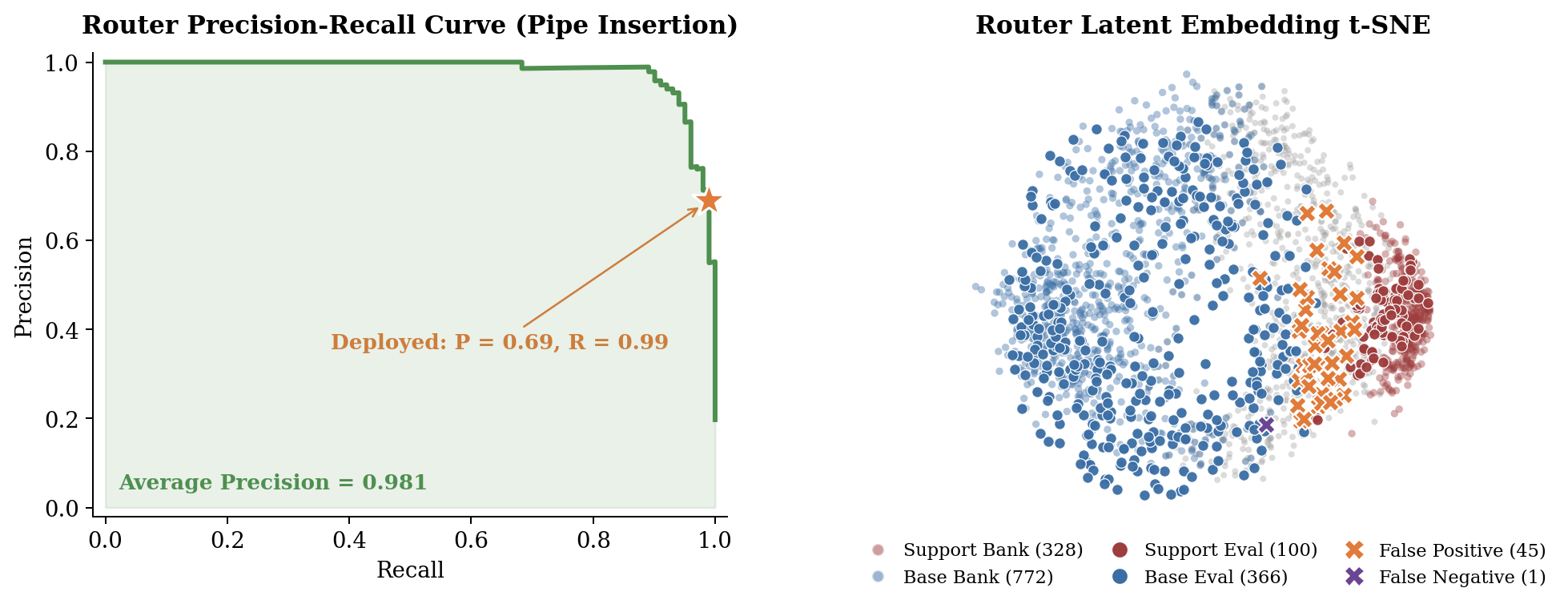
Router Analysis
On a held-out teleoperated set with manually labeled support phases
(pipe insertion), the MLP router reaches 99.0% recall
and 69.0% precision, favoring early
support activation over missed handoffs. A t-SNE of the
router latents shows clear separation between base and
support states, with false positives concentrated near the
support-manifold boundary (transition states) rather than unrelated
base states — consistent with the nearest-neighbor
design.
Router Analysis. Precision-recall curve (left) and
t-SNE of router latents (right) for the pipe insertion task.
Paper
19 pages, including appendix. Scroll horizontally to flip through
pages.
BibTeX
@misc{surendran2026bridge,
title = {Bridging Handheld and Teleoperated Supervision for Contact-Rich Manipulation via State-Gated Experts},
author = {Surendran, Vidullan and Peri, Neehar and Watkins, David},
year = {2026},
}